
Offer-Ready Publisher
At Offer-Ready, we allow companies to find their optimal mobile phone tariff. We’ve developed a bunch of proprietary algorithms to search over millions of potential combinations of base tariffs and optional packs in under a tenth of a second.
We need to store which tariffs are available, and what they cost, in a format that’s easy for us to maintain. However, the calculation process needs it in a format which makes the calculation as quick as possible. Transformation from the first form to the second involves quite a few different steps, quite a lot of pre-calculation, and potentially quite a few hours of computer work.
Recently I created the “publisher” front-end software, which ties all these transformation steps together and makes them accessible via a GUI. The requirements were roughly this:
- The configurations are stored in a version control system. That way, if an error occurs, we can easily roll back to a version that works.
- Publishing takes some time, perhaps a few hours. Therefore a “synchronous” solution, where the user clicks and the HTTP response delivers the “success” or “failure” status, is not acceptable; HTTP requests should not last a few hours.
- During these hours, the calculation system should not be offline. Until a new publish is successful, similar to how MVCC works, the “last successful publish” is the current configuration version which is online; this configuration should be online until, in an “instant”, the old successful publish is replaced with the new successful publish.
A further advantage of storing the configuration in a version control system is that after a calculation has occurred, we know what version of the configuration it executed against. If a customer rings up and says “this calculation chose the wrong tariff!” we know which configuration that calculation was executed against. We can check the VCS logs: perhaps there was an error in the configuration which has already been corrected?
Here’s a screen shot of the publish screen:
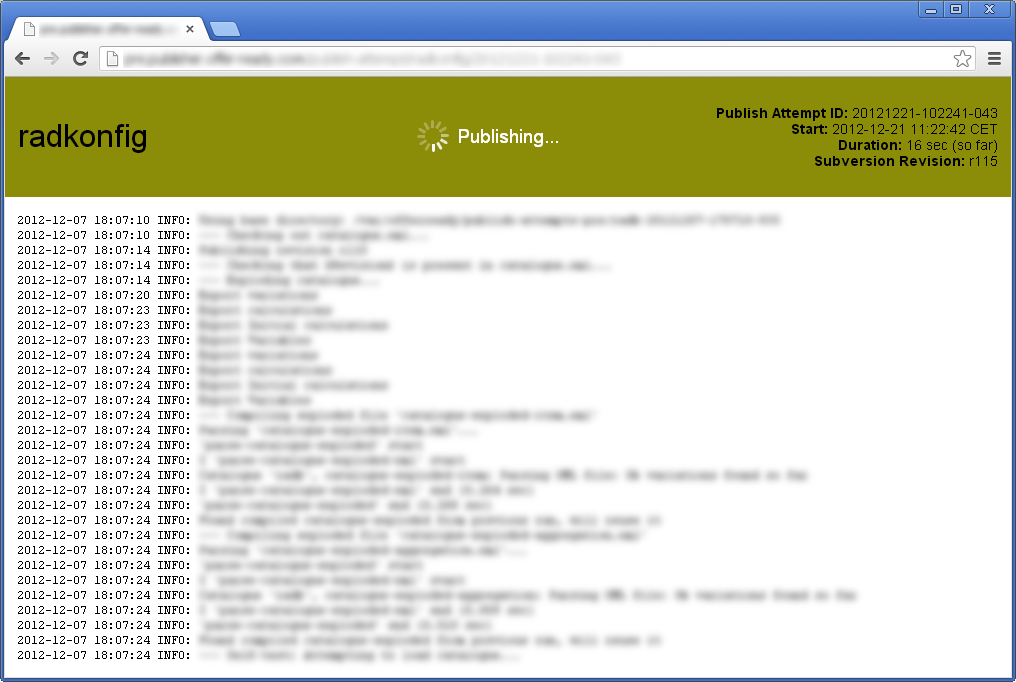
I designed and implemented the software for this publishing process. It works like this:
- Every time someone clicks publish, a process gets started to do the publish in the background.
- This process creates a new directory where it does its work (So all other directories, including previous successful publishes, are not affected.)
- This process writes a logfile
- The front-end simply reads this logfile, and displays it on the screen. (This is a simplification; various other files are written by the process so its status can be determined.)
- There is a database table describing which directory contains the last successful publish. Once a publish is successful, the process simply updates this table, to set its directory name as the successful publish.
- Before each calculation request, this database table is queried, and if the successful publish has changed since the last request, it “just-in-time” reloads the configuration with the newly published version.
- There are multiple web servers serving the customers and performing these calculations. This architecture means they query the central database, the central publisher doesn’t have to contact them. The provisioning process for a new web server doesn’t involve changing the central publisher at all.
This is the next generation of the algorithm described in the article Atomic operations over filesystem and database.